



神经网络组件
神经网络听起来极为复杂,但是我们将其归类解构后主要存在以下这几个核心组件,包括:
- 层:这是神经网络的基础结构,这是将输入张量变换为输出张量
- 模型:由大量的层构成的输入输出网络成为模型
- 损失函数:又称为目标函数,用于描述与真值的偏差
- 优化器:最小化损失值来学习各种参数,调整权重
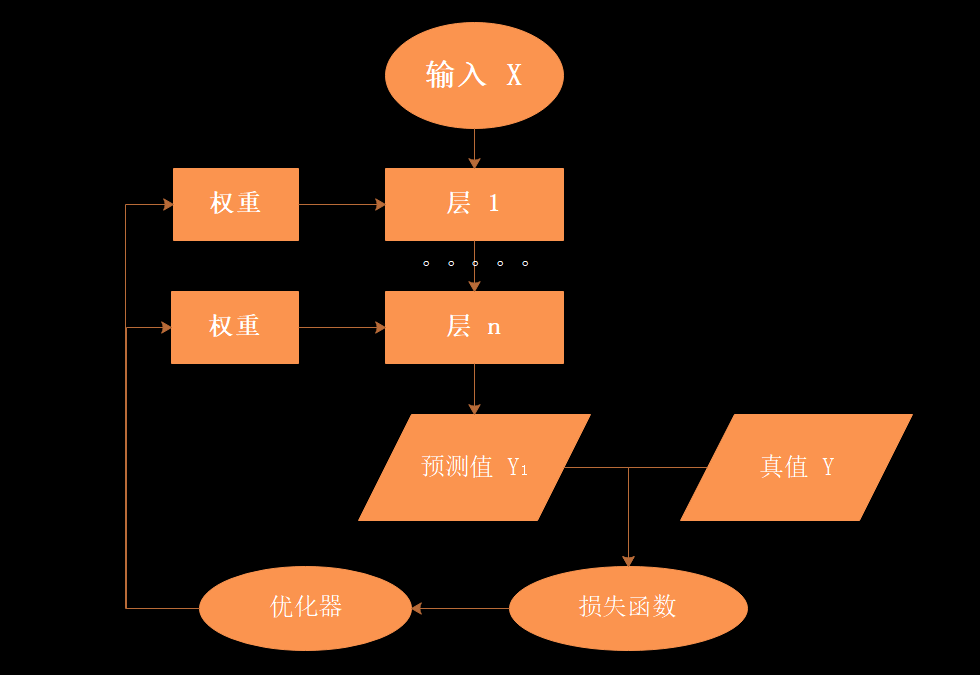
将以上的核心组件连接起来,就是最为简单的一个神经网络,具体的流程是:
- 输入 X 首先通过由层组成的模型变换后输出一个预测值 Y1
- 损失函数将预测值 Y1 与 真值 Y 进行比较,得到损失值(这个值可以是距离、概率值等量化值),该损失值衡量了预测值与目标结果的匹配或相似程度
- 优化器利用损失值更新参数与权重,为了在新的一轮输入中,基于新的参数与权重获得的损失值下降。逐渐逼近真值。
- 通过不断的循环训练,直到损失值到达一个阈值或者循环次数后,结束训练。
PyTorch 神经网络工具
相对应到实际的编程中也是将以上的步骤具体化,例如下图中的构建流程与主要的函数。
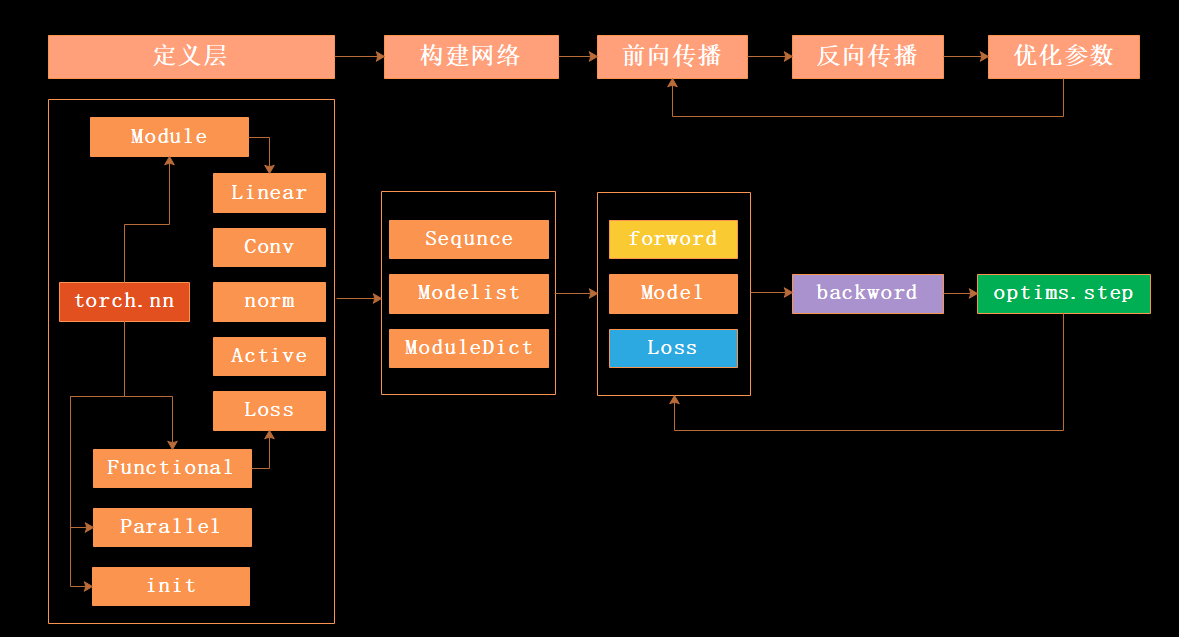
由上图可以看到在 pytorch 工具箱中已经定义好了一些常用的网络层,例如:全连接层、卷积层、正则化层、激活层等,基于这些工具,我们只要选择需要的层即可快速的构建神经网络。
构建网络
在 Pytorch 中有比较多的方法来构建模型,但是一般我们会约定几种常见的构建方法来提高代码的维护性。主要存在以下四种方法:
这里我们假设构建一个模型为:卷积层 --> Relu层 --> 池化层 --> 全连接层 --> Relu层 --> 全连接层
导入的头文件都是相同的:
import torch
import torch.nn.functional as F
from collections import OrderedDict
方法一:
这种方法较为常见,通过逐条的罗列出网络层,在 forward 中将它们连接起来
class Net1(torch.nn.Module):
def __init__(self):
super(Net1, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 32, 3, 1, 1)
self.dense1 = torch.nn.Linear(32 * 3 * 3, 128)
self.dense2 = torch.nn.Linear(128, 10)
model1 = Net1()
print(model1)

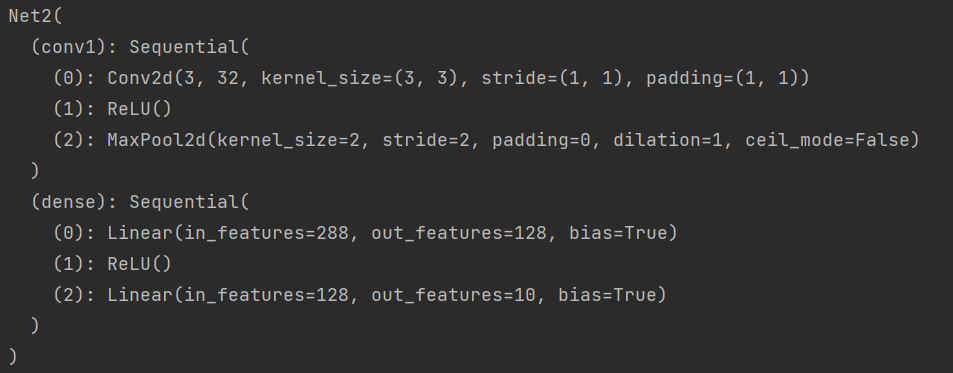
方法二:
还可以采用 torch.nn.Sequential 来构建网络层进行快速构建,也方便模块化复用,但是每层的编号是数字,在检查模型时,不易区分
class Net2(torch.nn.Module):
def __init__(self):
super(Net2, self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(3, 32, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2))
self.dense = torch.nn.Sequential(
torch.nn.Linear(32 * 3 * 3, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 10)
)
model2 = Net2()
print(model2)
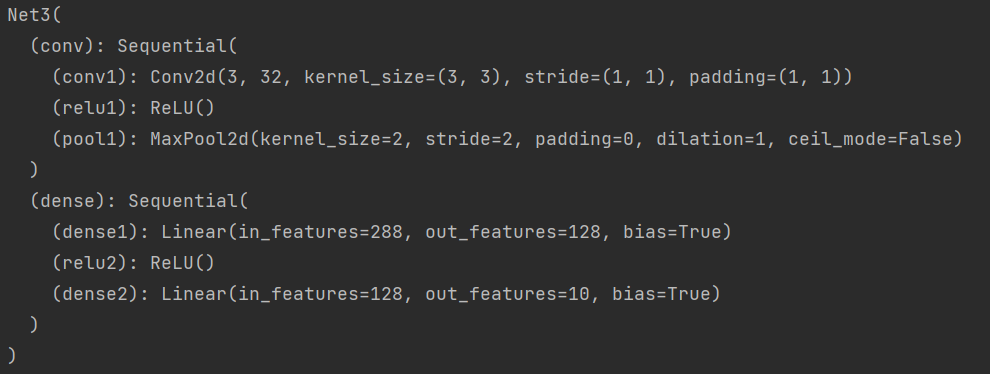
方法三:
这个方法则是采用 add_module() 来添加每一层,并为每一层添加一个名称
class Net3(torch.nn.Module):
def __init__(self):
super(Net3, self).__init__()
self.conv = torch.nn.Sequential()
self.conv.add_module("conv1", torch.nn.Conv2d(3, 32, 3, 1, 1))
self.conv.add_module("relu1", torch.nn.ReLU())
self.conv.add_module("pool1", torch.nn.MaxPool2d(2))
self.dense = torch.nn.Sequential()
self.dense.add_module("dense1", torch.nn.Linear(32 * 3 * 3, 128))
self.dense.add_module("relu2", torch.nn.ReLU())
self.dense.add_module("dense2", torch.nn.Linear(128, 10))
model3 = Net3()
print(model3)
方法四:
这里则是通过字典的形式添加每一层,并且设置每层名称。
class Net4(torch.nn.Module):
def __init__(self):
super(Net4, self).__init__()
self.conv = torch.nn.Sequential(
OrderedDict(
[
("conv1", torch.nn.Conv2d(3, 32, 3, 1, 1)),
("relu1", torch.nn.ReLU()),
("pool", torch.nn.MaxPool2d(2))
]
))
self.dense = torch.nn.Sequential(
OrderedDict([
("dense1", torch.nn.Linear(32 * 3 * 3, 128)),
("relu2", torch.nn.ReLU()),
("dense2", torch.nn.Linear(128, 10))
])
)
model4 = Net4()
print(model4)
前向传播
当定义好网络层后,还需要将它们通过前向传播的方式串联起来,实现信息的前向传导。一般该函数的形参为输入数据,返回值为输出数据。
因为网络中存在一些层是没有需要学习参数的,所以也可以直接使用 nn.functional 来定义,不需要实例化。
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv(x)), 2)
x = x.view(x.size(0), -1) // 将数据展平,送入全连接层
x = F.relu(self.dense1(x))
x = self.dense2(x)
return x
def forward(self, x):
conv_out = self.conv1(x)
res = conv_out.view(conv_out.size(0), -1)
out = self.dense(res)
return out
反向传播
在 Pytorch 中提供了自动反向传播的功能,直接让损失函数调用 backword() 即可
优化器
Pytorch 将常用的优化器都分装在 torch.optim 中,包括常见的 SGD、Adam、RMSProp等。
一般使用优化器的步骤如下:
import torch.optim as optim # 导入模块
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # 选择优化器
out = model(img) # 前向传播
loss = loss_func(out, label) # 计算损失值
optimizer.zero_grad() # 清空梯度
loss.backword() # 反向传播
optimizer.step() # 优化器跟新参数
训练模型
模型具有两种形态:训练模式、测试或验证模式。它们的区别在于是否会反向传播而更新模型参数与权重。
在训练模式下,调用 model.train() 即可。而在测试或验证模式下时,调用 model.evel() ,这将会把所有的 training 属性设置为 False
评论区