



简介
ViT 是由 Google 在 ICLR 2021 所发表的工作,实现了 Transformer 应用在图像分类的模型。虽然这不是第一篇将 Transformer 用于视觉领域的方案,但是由于其模型采用了较少的修改,并实现的效果好,扩展性强,成为了Vision Transformer 的里程碑。
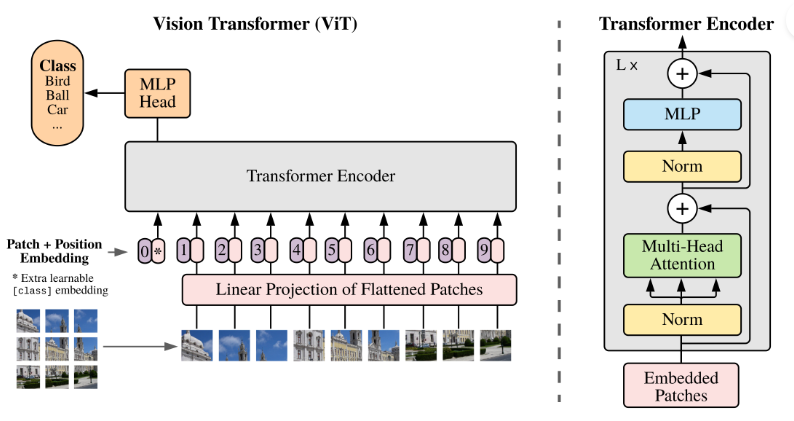
简单描述算法流程:将整幅图像拆分成小图像块,然后把这些小图像块的线性嵌入序列作为 Transformer 网络的输入,然后使用监督学习的方式进行图像分类的训练。如下图所示:
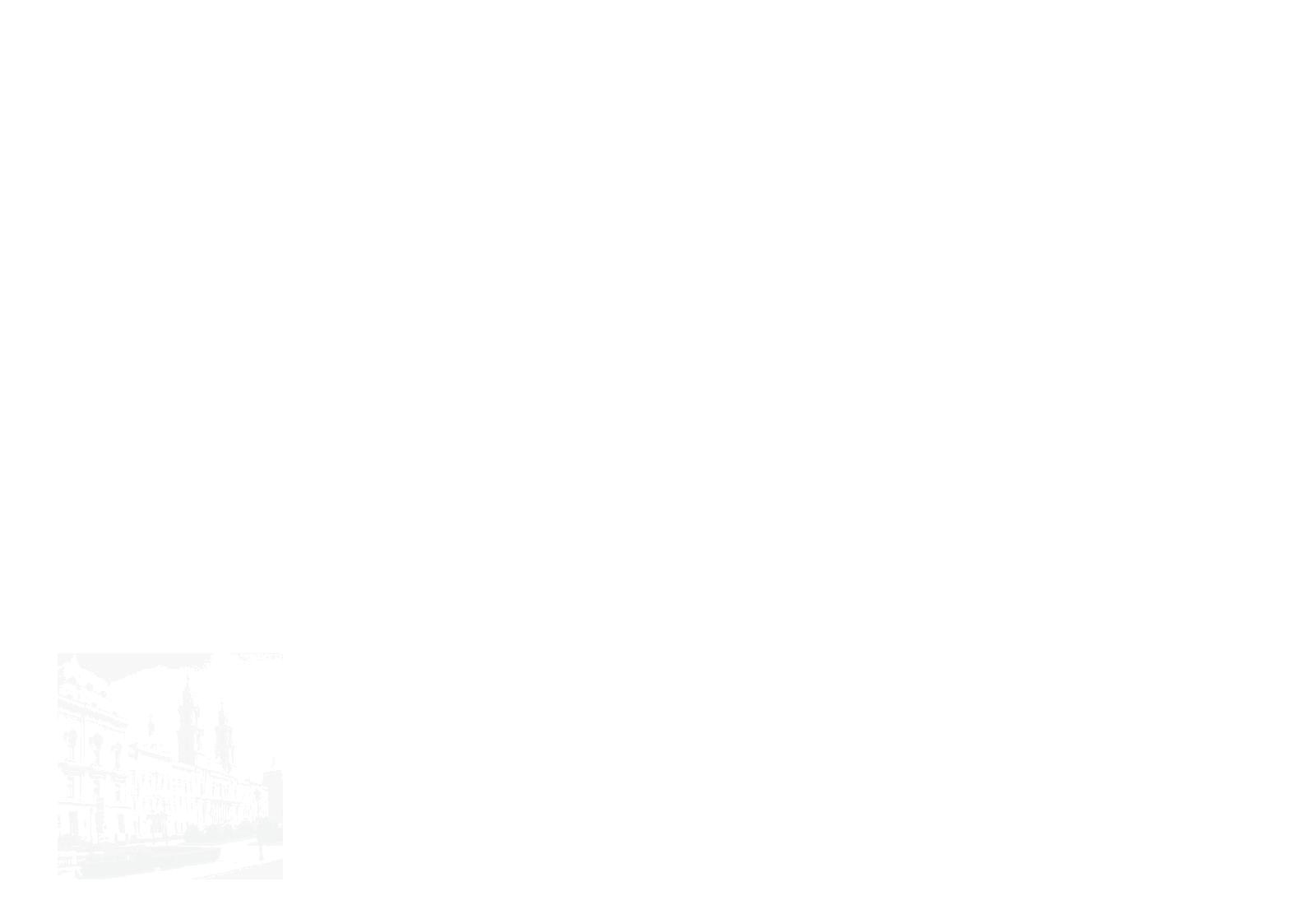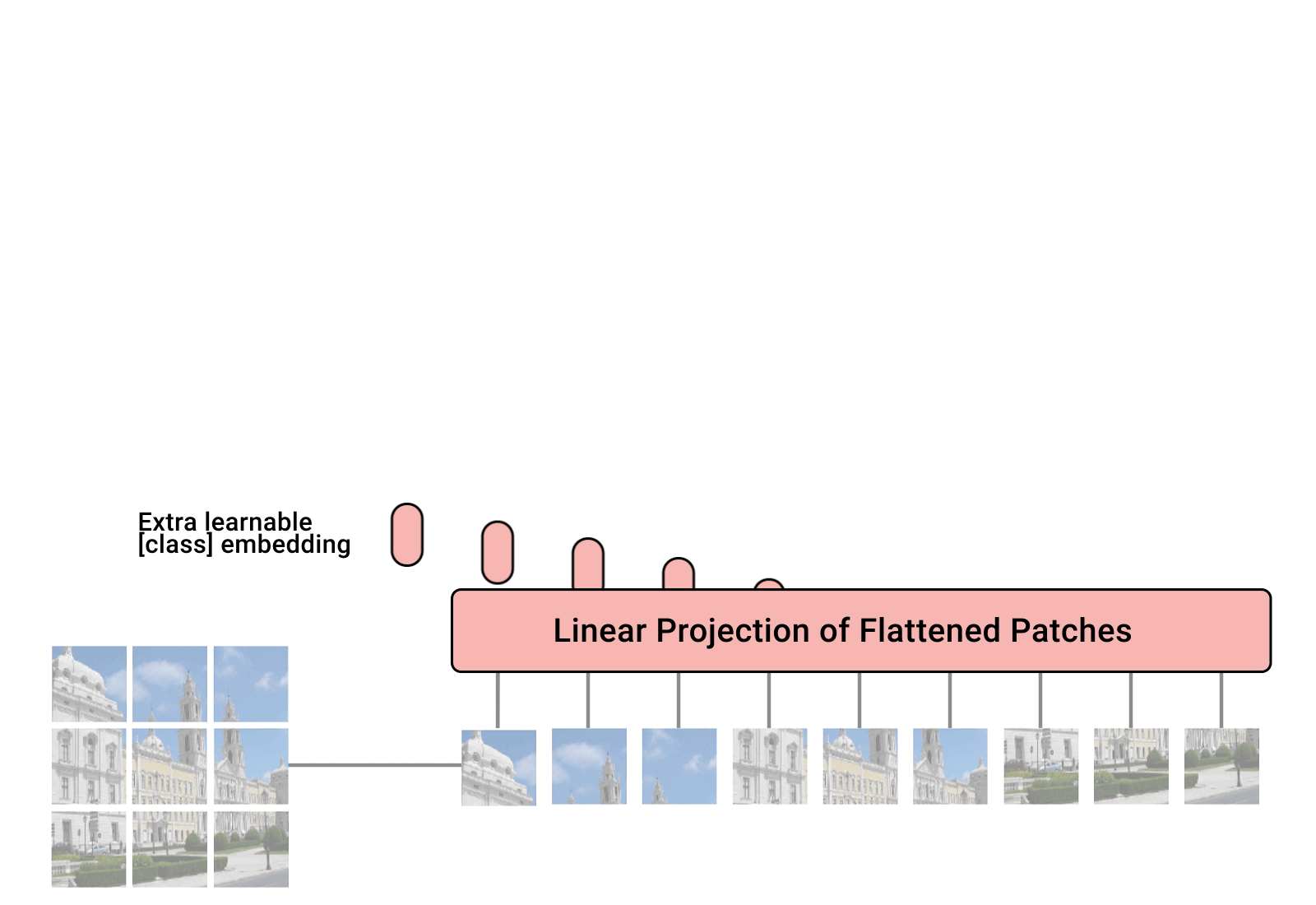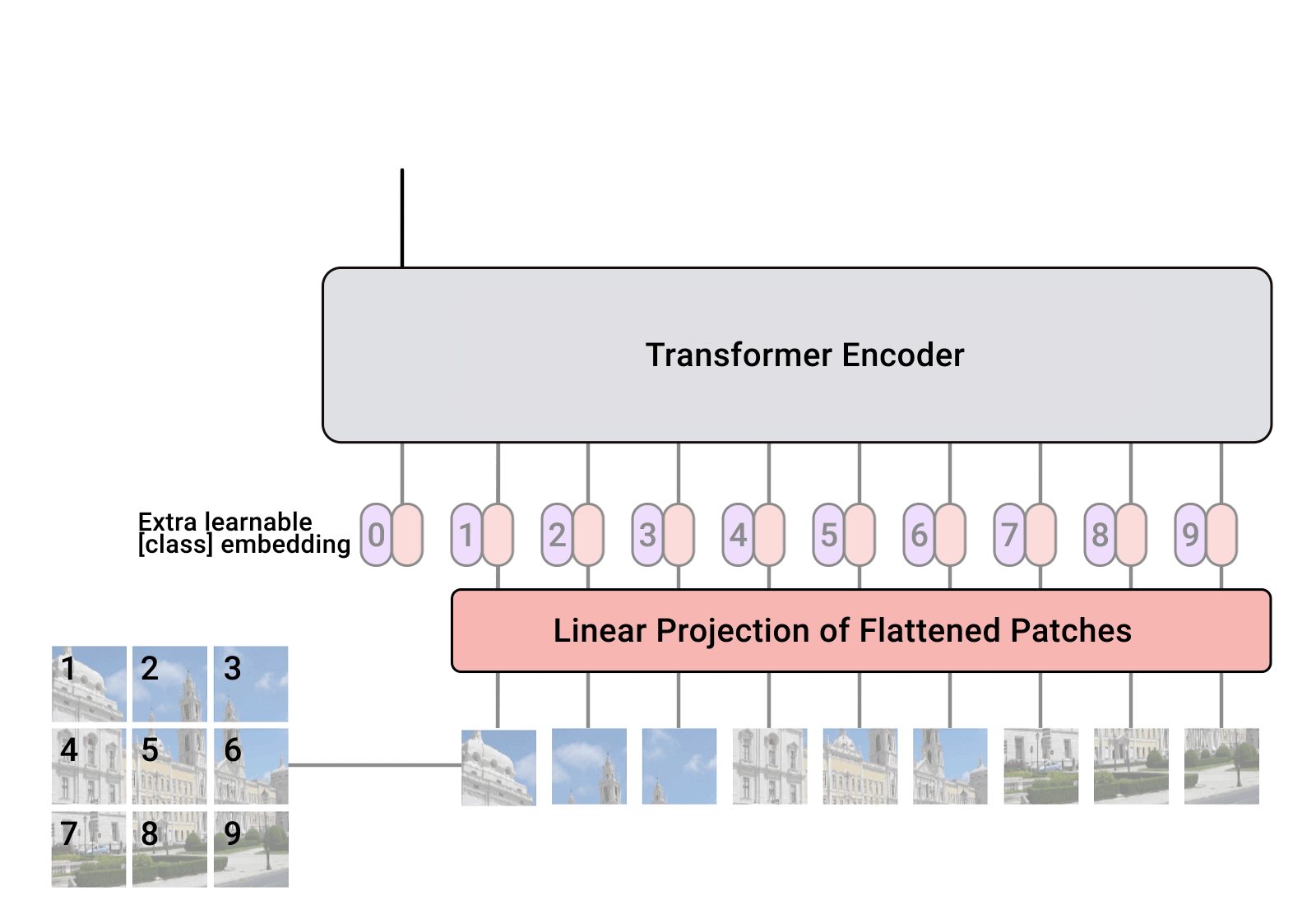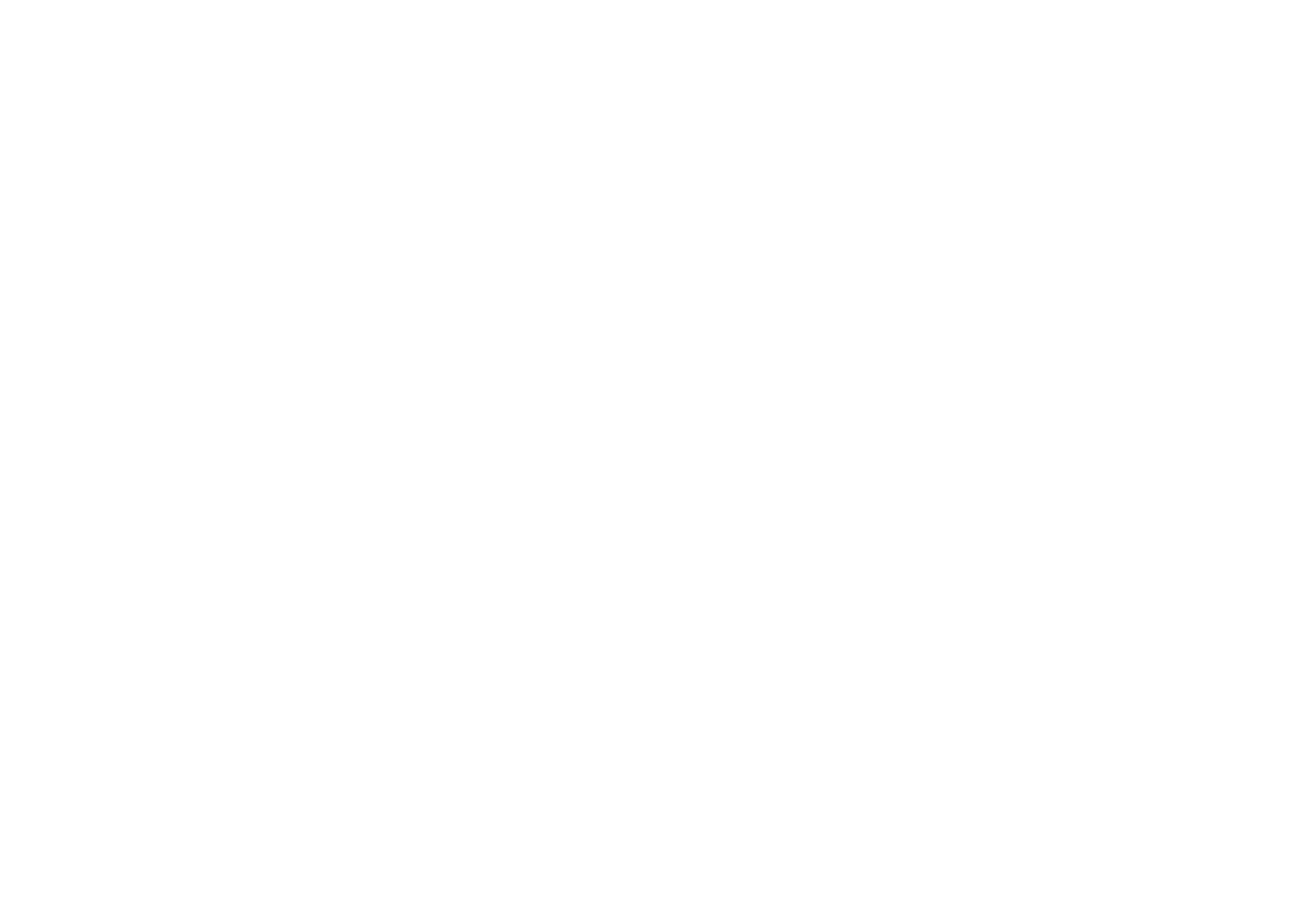
从论文可以得出结论,当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少一定的平移不变性和局部感知性的限制,可以在下游任务中获得较好的迁移效果。
具体结构
以下公式是对整体的公式化描述:
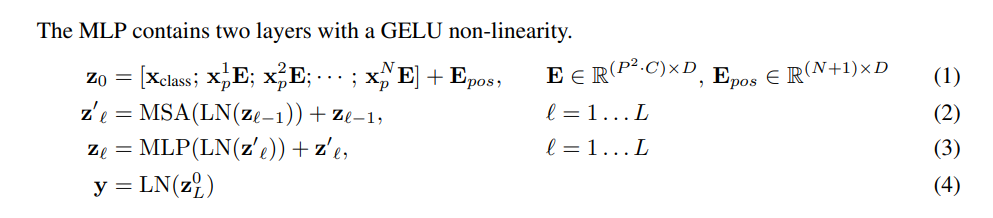
图像分块嵌入
在 Transformer 输入时是二维数组,表示为 ,其中 为序列长度, 为序列的维度。所以首先我们要将一个 大小的图片转化为 数组。
具体方法是将图片划分为 大小的 patch 方块,再将其展平,即 。而维度为 ,再做一个线性变换,将维度压缩为 即可。例如:
- 例如输入图片大小为224x224,固定 patch 大小为16x16
- 每张图像会生成224x224/16x16=196个 patch,即输入序列长度为196,维度 16x16x3=768
- 且线性投射层的维度为768xN (N=768),即大小依然为196x768,即一共有196个token,维度是768。
- 还需要加上一个特殊字符 cls(class token),用于最后分类,因此最终的维度是197x768。
具体代码中,则是直接利用一个卷积层来实现全部要求:
# 图像分块、Embedding
class PatchEmbed(nn.Layer):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
# 原始大小为int,转为tuple,即:img_size原始输入224,变换后为[224,224]
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
# 图像块的个数
num_patches = (img_size[1] // patch_size[1]) * \
(img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
# kernel_size=块大小,即每个块输出一个值,类似每个块展平后使用相同的全连接层进行处理
# 输入维度为3,输出维度为块向量长度
# 与原文中:分块、展平、全连接降维保持一致
# 输出为[B, C, H, W]
self.proj = nn.Conv2D(
in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# [B, C, H, W] -> [B, C, H*W] ->[B, H*W, C]
x = self.proj(x).flatten(2).transpose((0, 2, 1))
return x
位置编码
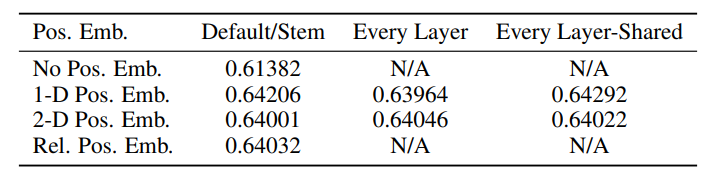
论文测试了不同的编码方式对精度的影响。
- 1-D 位置编码:例如3x3共9个patch,patch编码为1到9
- 2-D 位置编码:patch编码为11,12,13,21,22,23,31,32,33,即同时考虑X和Y轴的信息,每个轴的编码维度是D/2
实际实验结果表明,不管使用哪种位置编码方式,模型的精度都很接近,甚至不适用位置编码,模型的性能损失也没有特别大。原因可能是ViT是作用在image patch上的,而不是image pixel,对网络来说这些patch之间的相对位置信息很容易理解,所以使用什么方式的位置编码影像都不大
其他的编码
使用正弦和余弦函数来生成位置编码。具体而言,对于每个位置,位置编码由两个向量组成,一个用于编码正弦函数,一个用于编码余弦函数。这两个向量的维度与输入特征的维度相同。
PE(pos, 2i) = sin(pos / (10000^(2i/d_model)))
PE(pos, 2i+1) = cos(pos / (10000^(2i/d_model)))
其中,pos 表示位置(patch数量),i 表示位置编码向量的索引,d_model 表示输入特征的维度。
这样的设计使得不同位置之间的编码值在不同维度上具有不同的频率,从而使模型能够学习到不同位置之间的相对位置关系。
通过将位置编码向量与输入特征相加,位置信息就被嵌入到输入特征中了。这样,Transformer模型在进行自注意力计算时,可以通过位置编码了解输入序列的顺序和位置关系。
Transformer Encoder Block
成功将图片转化为二维数组序列后,就可以将其输入到 Transformer Encoder 中了,一个标准的 Transformer Encoder 包括了:LN/multi-head attention/LN/MLP
Multi-head Attention
Transformer Encoder 中最重要的结构就是 Multi-head Attention,即多头注意力结构。先将输入映射到q,k,v,如果只有一个头,qkv的维度都是197x768,如果有12个头(768/12=64),则qkv的维度是197x64,一共有12组qkv,最后再将12组qkv的输出拼接起来,输出维度是197x768,然后在过一层LN,维度依然是197x768。
通过使用该机制能够有效的建立全局特征联系,捕捉长距离依赖关系,并且灵活地学习到不同类型和层次的特征表示,提升模型的表达能力和泛化能力。
MLP
操作是将维度放大再缩小回去,197x768放大为197x3072,再缩小变为197x768。
使用MLP的原因是为了增加模型的非线性能力,以更好地适应图像数据的复杂性。MLP可以对每个位置上的特征进行非线性映射和变换,从而提取和编码更丰富的特征表示。
综上,可以看出通过一个 Transformer Encoder Block 处理之后的维度依然和输入相同,都是197x768,因此可以堆叠多个 block,来提高模型性能。
MLP Head
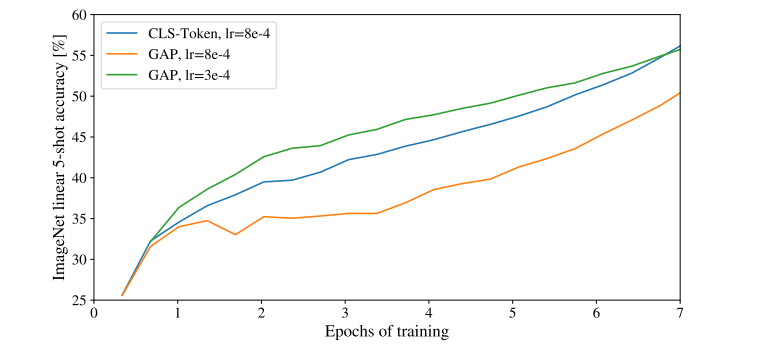
最后会将特殊字符 cls 对应的输出作为encoder的最终输出,因为我们认为通过自注意力模块的学习,cls 能够对全局信息进行表示。
当然,我们还可以通过对所有的信息进行处理来预测分类。论文中还测试了 Global Average Pooling 进行预测,可以看到它们的效果相差不大,但是计算量前者更小。
Reference:
1、ViT(Vision Transformer)解析
2、Transformer详解
3、关于ViT(Vision Transformer)的算法解读
4、通用 Vision Backbone 超详细解读
评论区