



数据处理工具
在 Pytorch 中,主要使用的数据工具有 util.data 和 torchvision,涉及了数据装载、数据预处理、输出增强等。它们的主要功能函数与相互关系如下:
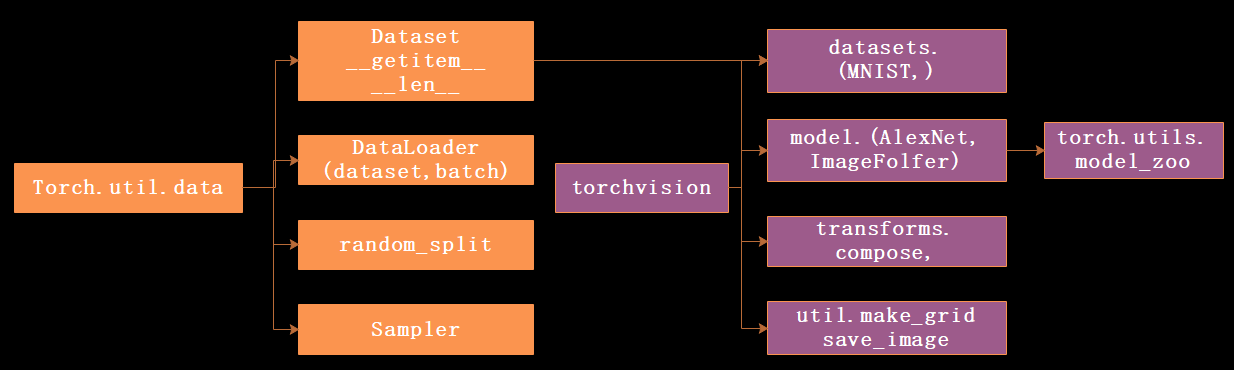
util.data 模块
包括以下4个基本类:
- Dataset:抽象类,无法直接实例化,需要继承该类,复写其中的两个方法
__getitem__、__len__ - DataLoader:一个数据迭代器,实现批量(batch)读取,打乱数据(shuffle)并且提供并行加速等功能
- random_split:将数据集随机拆分为给定长度的非重叠的新数据集
- Sample:包括多种采样函数
Dataset 定义
import torch
from torch.utils import data
import numpy as np
class TestDataset(data.Dataset): # 继承 Dataset 类
def __init__(self):
# 创建数据与标签
self.Data = np.asarray([[1, 2], [3, 2], [4, 1], [2, 3], [4, 3], [1, 3]])
self.Label = np.asarray([[0, 1], [1, 0], [1, 1], [0, 1], [1, 0], [1, 0]])
def __getitem__(self, item):
# 将数据转化为 Tensor
txt = torch.from_numpy(self.Data)
label = torch.from_numpy(self.Label[index])
return txt, label
def __len__(self):
return len(self.Data)
test = TestDataset()
print(test[2]) # 相当于调用了 __getitem__(2),返回一个元组数据
print(test.__len__())
输出:
(tensor([4, 1], dtype=torch.int32), tensor([1, 1], dtype=torch.int32))
6
DataLoader 定义
以上 Dataset 只负责数据的抽取,每次只能返回一个样本。而 DataLoader 则可以实现批量处理,并同时进行 shuffle 和并行加速等操作。 DataLoader 的定义如下:
def __init__(self, dataset: Dataset[T_co], batch_size: Optional[int] = 1,
shuffle: bool = False, sampler: Union[Sampler, Iterable, None] = None,
batch_sampler: Union[Sampler[Sequence], Iterable[Sequence], None] = None,
num_workers: int = 0, collate_fn: Optional[_collate_fn_t] = None,
pin_memory: bool = False, drop_last: bool = False,
timeout: float = 0, worker_init_fn: Optional[_worker_init_fn_t] = None,
multiprocessing_context=None, generator=None,
*, prefetch_factor: int = 2,
persistent_workers: bool = False):
主要的参数包括:
- dataset:需要加载的数据集
- batch_size:批大小
- shuffle:是否打乱数据
- sampler:样本抽样
- num_workers:使用多线程加载,0表示不使用多线程
- pin_memory:是否将数据保存到 pin memory区,这样数据到 GPU 会更快
- drop_last:丢弃不足批大小的数据
test_loader = data.DataLoader(test, batch_size=2, shuffle=True, num_workers=0)
for step, (batch_x, batch_y) in enumerate(test_loader):
print(step, batch_x, batch_y)
输出:
0 tensor([[1, 3],
[4, 1]], dtype=torch.int32) tensor([[1, 0],
[1, 1]], dtype=torch.int32)
1 tensor([[3, 2],
[2, 3]], dtype=torch.int32) tensor([[1, 0],
[0, 1]], dtype=torch.int32)
2 tensor([[4, 3],
[1, 2]], dtype=torch.int32) tensor([[1, 0],
[0, 1]], dtype=torch.int32)
torchvision 模块
包括以下4个基本类:
- datasets:提供常用数据集加载,主要包括:MNIST、CIFAR10/100、ImageNet、COCO等
- models:提供经典网络结构和预训练好的模型,主要包括:AlexNet、VGG、ResNet、Inception等
- transfrom:常用的数据预处理工具,主要包括对 Tensor 及 OIL Image 对象的操作
- utils:
make_grid方法能够将多张图片拼接在一个网格中。save_image能够将 Tensor 保存为图片
评论区